
Why AI Control Matters More Than AI Content: GPUs, World Models, and the Future of Smart Audio
From GPUs and TPUs to World Models — and Why AmpVortex Is Built for What Comes Next
Introduction: We’re Obsessed with What AI Creates — Not What It Controls
AI-generated music, images, and films have captured the world’s attention. Tools for AI Compose and AI Film demonstrate astonishing creative capability. But creation, however impressive, is only the surface layer of a deeper transformation.
The true inflection point in artificial intelligence is not content generation, but control.
Content is static.
Control is embodied.
Content is consumed.
Control reshapes environments.
This distinction matters not only to AI researchers, but to the future of home audio, multi-room systems, and intelligent living spaces.

Layer One: Compute — Where the Power Struggle Actually Begins
GPUs and the Rise of NVIDIA
Modern AI exists because of parallel computation. Matrix math, not magic, powers intelligence—and no company has shaped this reality more than NVIDIA.
NVIDIA’s dominance extends far beyond silicon:
- CUDA defines the de facto AI software stack
- Training and inference pipelines converge on NVIDIA GPUs
- AI music, video, and control models overwhelmingly depend on this ecosystem
But the next phase of AI is exposing a new constraint: latency.
Groq: Why Inference Speed Changes the Game
Groq represents a fundamentally different AI philosophy. Its focus is not massive training throughput, but deterministic, ultra-low-latency inference.
This matters because:
- Real-world control systems cannot tolerate unpredictable delays
- Inference must happen in real time, not “eventually”
Crucially, Groq’s CEO Jonathan Ross was one of the original architects of Google’s TPU, giving Groq deep roots in practical AI acceleration rather than theoretical scale.
NVIDIA’s response to Groq has been strategic rather than dismissive:
- Stronger inference-optimized GPUs
- Software-level latency optimizations
- Positioning GPUs as universal engines across training and control
This is not a benchmark war.
It is a fight over who owns real-time decision-making.
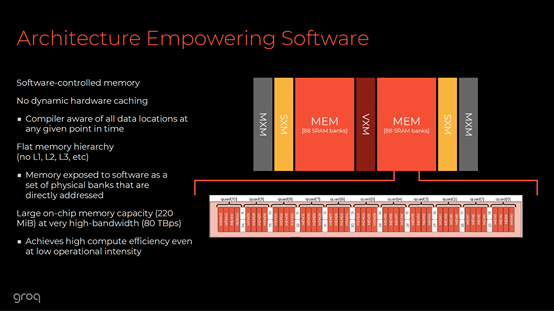
Google TPU: Centralized Intelligence at Scale
Google’s Tensor Processing Units (TPUs) were designed for cloud-scale inference:
- Highly efficient at massive batch processing
- Optimized for centralized services such as MusicLM and large language models
TPUs excel at thinking at scale, but they are not designed for distributed, room-by-room, millisecond-sensitive control.
TPUs are powerful brains.
They are not nervous systems.
Layer Two: Models — From Output to Understanding
AI Content Models: Impressive, but Passive
AI Compose and AI Film systems rely on:
- Diffusion models
- Large Transformers
- Enormous compute budgets
They generate:
- Music
- Images
- Video
Once generated, content stops acting. It does not adapt, anticipate, or respond.
World Models: Intelligence That Understands Environments
World models represent a deeper shift in AI research:
- They simulate how environments evolve
- They predict the consequences of actions
- They enable planning rather than output
This paradigm is strongly associated with researchers like Yann LeCun, who has repeatedly argued that language-only models cannot deliver general intelligence.
World models are essential for:
- Robotics
- Autonomous systems
- Smart environments
- Adaptive home automation
They are the foundation of AI control.
Layer Three: AI Control — When Intelligence Becomes Physical
AI control systems do not wait for commands. They:
- Observe context
- Predict intent
- Act proactively
In a smart home, this means:
- Not “play music in the living room”
- But “it’s evening, people are gathering, lighting is dimming—adjust zones, volume, and spatial balance”
This is not content generation.
This is experience orchestration.
Why Audio Is the Ideal Control Surface
Sound is:
- Continuous
- Spatial
- Contextual
- Emotional
Unlike screens, audio exists around us.
That makes multi-room audio systems the most natural execution layer for AI control.
AmpVortex: Built for Control, Not Just Playback
AmpVortex is not designed as a passive amplifier ecosystem. It is built as a distributed execution platform.
Core design principles:
- Multi-zone by default
- API-first control architecture
- Multi-protocol streaming resilience
- Deterministic, low-latency behavior
This makes AmpVortex inherently aligned with AI-driven control systems—even before AI is explicitly integrated.
The AmpVortex Lineup — One Architecture, Two Power Envelopes
AmpVortex-16060 / 16060A / 16060G
The AmpVortex-16060 series delivers 65 watts per channel, optimized for:
- Medium-sized rooms
- High-efficiency speakers
- Distributed multi-room playback
- Continuous, adaptive audio scenes
At this power level, the system excels where consistency and spatial accuracy matter more than peak output.
The “A” variants prioritize immersive cinema and Atmos-centric layouts.
The “G” variants emphasize multi-protocol streaming stability and redundancy.
AmpVortex-16100 / 16100A / 16100G
The AmpVortex-16100 series increases output to 110 watts per channel, while maintaining the same architecture and control model as the 16060 line.
This additional power expands the system’s operating envelope, enabling:
- Larger rooms with greater air volume
- Lower-sensitivity or impedance-challenging speakers
- Sustained high-dynamic-range cinema playback
- AI-controlled scenarios where multiple zones peak simultaneously
From an AI control perspective, this is not a feature difference—it is a margin-of-error difference.
Why Power Headroom Is a Control Variable
AI control systems anticipate and overlap actions.
They do not behave like cautious human operators.
Power headroom determines:
- How aggressively a system can act
- How safely it can stack spatial effects
- How predictably it can operate under uncertainty
In this sense, the difference between 65W and 110W per channel is not philosophical.
It is operational.
Conclusion: Control Is the Endgame
AI content will become:
- Cheaper
- Faster
- Ubiquitous
AI control will remain:
- Rare
- Complex
- System-defining
The future belongs to systems that can:
- Respond in real time
- Coordinate across spaces
- Integrate perception, decision, and action
AmpVortex is built for that future—not because it chases AI trends, but because its architecture assumes intelligence will arrive.
Suggested Internal Links
References
- Groq 14nm Chip Gets 6x Boost: Launches Llama 3.3 70B on GroqCloud, accessed December 25, 2025, https://groq.com/blog/groq-first-generation-14nm-chip-just-got-a-6x-speed-boost-introducing-llama-3-1-70b-speculative-decoding-on-groqcloud
- Llama-3.3-70B-SpecDec – GroqDocs, accessed December 25, 2025, https://console.groq.com/docs/model/llama-3.3-70b-specdec
- Introducing Cerebras Inference: AI at Instant Speed, accessed December 25, 2025, https://www.cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed
- Evaluating Llama‑3.3‑70B Inference on NVIDIA H100 and A100 GPUs – Derek Lewis, accessed December 25, 2025, https://dlewis.io/evaluating-llama-33-70b-inference-h100-a100/
- Unlocking the full power of NVIDIA H100 GPUs for ML inference with TensorRT – Baseten, accessed December 25, 2025, https://www.baseten.co/blog/unlocking-the-full-power-of-nvidia-h100-gpus-for-ml-inference-with-tensorrt/
- Why Meta AI’s Llama 3 Running on Groq’s LPU Inference Engine Sets a New Benchmark for Large Language Models | by Adam | Medium, accessed December 25, 2025, https://medium.com/@giladam01/why-meta-ais-llama-3-running-on-groq-s-lpu-inference-engine-sets-a-new-benchmark-for-large-2da740415773
- Groq Says It Can Deploy 1 Million AI Inference Chips In Two Years – The Next Platform, accessed December 25, 2025, https://www.nextplatform.com/2023/11/27/groq-says-it-can-deploy-1-million-ai-inference-chips-in-two-years/
- Inside the LPU: Deconstructing Groq’s Speed | Groq is fast, low cost inference., accessed December 25, 2025, https://groq.com/blog/inside-the-lpu-deconstructing-groq-speed
- Determinism and the Tensor Streaming Processor. – Groq, accessed December 25, 2025, https://groq.sa/GroqDocs/TechDoc_Predictability.pdf
- What is a Language Processing Unit? | Groq is fast, low cost inference., accessed December 25, 2025, https://groq.com/blog/the-groq-lpu-explained
- LPU | Groq is fast, low cost inference., accessed December 25, 2025, https://groq.com/lpu-architecture
- GROQ-ROCKS-NEURAL-NETWORKS.pdf, accessed December 25, 2025, http://groq.com/wp-content/uploads/2023/05/GROQ-ROCKS-NEURAL-NETWORKS.pdf
- Groq Pricing and Alternatives – PromptLayer Blog, accessed December 25, 2025, https://blog.promptlayer.com/groq-pricing-and-alternatives/
- Comparing AI Hardware Architectures: SambaNova, Groq, Cerebras vs. Nvidia GPUs & Broadcom ASICs | by Frank Wang | Medium, accessed December 25, 2025, https://medium.com/@laowang_journey/comparing-ai-hardware-architectures-sambanova-groq-cerebras-vs-nvidia-gpus-broadcom-asics-2327631c468e
- The fastest big model bombing site in history! Groq became popular overnight, and its self-developed LPU speed crushed Nvidia GPUs, accessed December 25, 2025, https://news.futunn.com/en/post/38148242/the-fastest-big-model-bombing-site-in-history-groq-became
- New Rules of the Game: Groq’s Deterministic LPU™ Inference Engine with Software-Scheduled Accelerator & Networking, accessed December 25, 2025, https://ee.stanford.edu/event/01-18-2024/new-rules-game-groqs-deterministic-lputm-inference-engine-software-scheduled
- TPU vs GPU : r/NVDA_Stock – Reddit, accessed December 25, 2025, https://www.reddit.com/r/NVDA_Stock/comments/1p66o4e/tpu_vs_gpu/
- GPU and TPU Comparative Analysis Report | by ByteBridge – Medium, accessed December 25, 2025, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a
- Google TPU vs NVIDIA GPU: The Ultimate Showdown in AI Hardware – fibermall.com, accessed December 25, 2025, https://www.fibermall.com/blog/google-tpu-vs-nvidia-gpu.htm
- Cerebras CS-3 vs. Groq LPU, accessed December 25, 2025, https://www.cerebras.ai/blog/cerebras-cs-3-vs-groq-lpu
- The Deterministic Bet: How Groq’s LPU is Rewriting the Rules of AI Inference Speed, accessed December 25, 2025, https://www.webpronews.com/the-deterministic-bet-how-groqs-lpu-is-rewriting-the-rules-of-ai-inference-speed/
- Best LLM inference providers. Groq vs. Cerebras: Which Is the Fastest AI Inference Provider? – DEV Community, accessed December 25, 2025, https://dev.to/mayu2008/best-llm-inference-providers-groq-vs-cerebras-which-is-the-fastest-ai-inference-provider-lap
- Groq Launches Meta’s Llama 3 Instruct AI Models on LPU™ Inference Engine, accessed December 25, 2025, https://groq.com/blog/12-hours-later-groq-is-running-llama-3-instruct-8-70b-by-meta-ai-on-its-lpu-inference-enginge
- Groq vs. Nvidia: The Real-World Strategy Behind Beating a $2 Trillion Giant – Startup Stash, accessed December 25, 2025, https://blog.startupstash.com/groq-vs-nvidia-the-real-world-strategy-behind-beating-a-2-trillion-giant-58099cafb602
- Performance — NVIDIA NIM LLMs Benchmarking, accessed December 25, 2025, https://docs.nvidia.com/nim/benchmarking/llm/latest/performance.html
- How Tenali is Redefining Real-Time Sales with Groq, accessed December 25, 2025, https://groq.com/customer-stories/how-tenali-is-redefining-real-time-sales-with-groq